summary informed book suggestions
uses LDA based topic modeling as a basis for book recommendations.



Python

uses LDA based topic modeling as a basis for book recommendations.
Python
This project seeks to determine an effective method for book recommendations based on summarization. Natural language processing is used to retrieve the overall topics of each book from its summary. The topics are compared in order to find similar themes and genres. I decided to explore this with two different datasets: one larger and one smaller. I was curious to see how the algorithm would perform with less books to choose from when making a recommendation.
The smaller dataset I chose came with three separate files (two of them were applicable here). The first consisted of the book's title and id, as well as every user's rating . The second contained the same book id along with some other information including the summary and image for the book. Since I didn't need every rating, but rather simply the average rating, I decided to create a new dataset from these two. To obtain the average rating, I looped through the first dataset as follows.
First, I read in both datasets into a pandas dataframe.

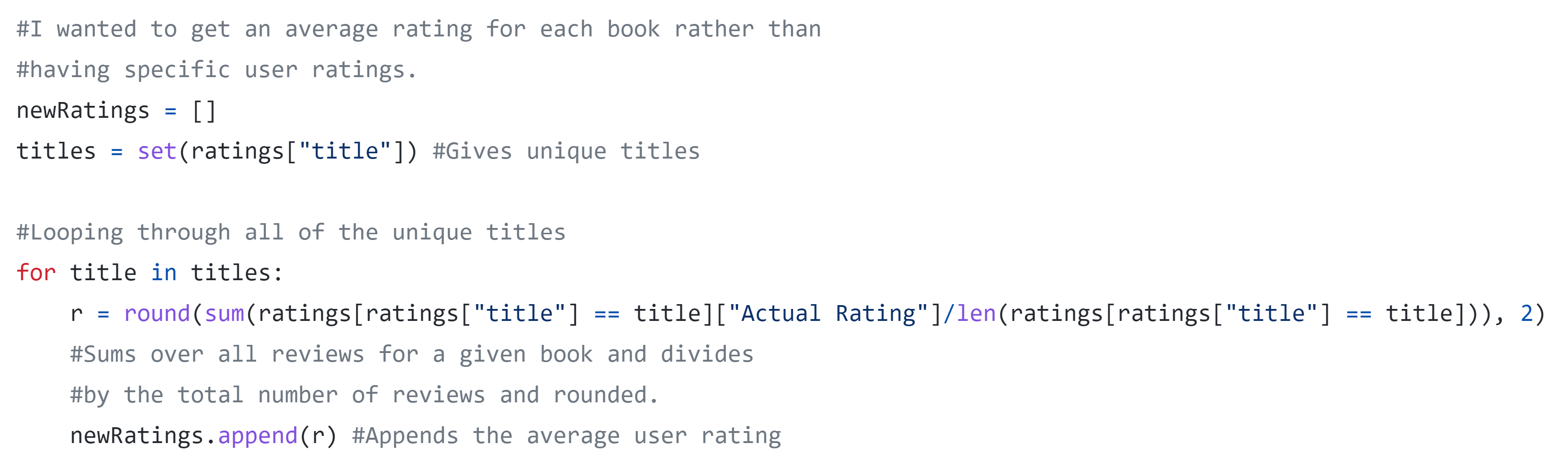
Now we have two dataframes each containing different information. The info data includes the summary and other relavant information while the ratings dataframe contains numerous ratings for each book provided by different readers. To obtain an average rating for each book, I looped through each of the unique titles in the data and took the average of all provided ratings as shown below.
Next, I created a new dataframe with only the information I wanted from the ratings data (the average ratings and the title of the book). I did this by first creating a dictionary with two keys each containing a list from the original ratings dataframe.

Finally, I merged this dataframe with the info data based on the title of each book. I decided to save my modified dataframe to a new csv file for easier use across multiple files.

After this process is finished, the new dataset looks like:

The other dataset I used did not need as much prep work, but was significantly larger. The following image shows the structure of this data.

Preprocessing for both datasets was fairly similar. The smaller dataset only had one unnecessary column that I removed. I also created duplicate of the summary column in order to preserve the original text because I thought it might be useful to display for the user later on. Finally, I changed the titles to be all lowercase for easier searching.

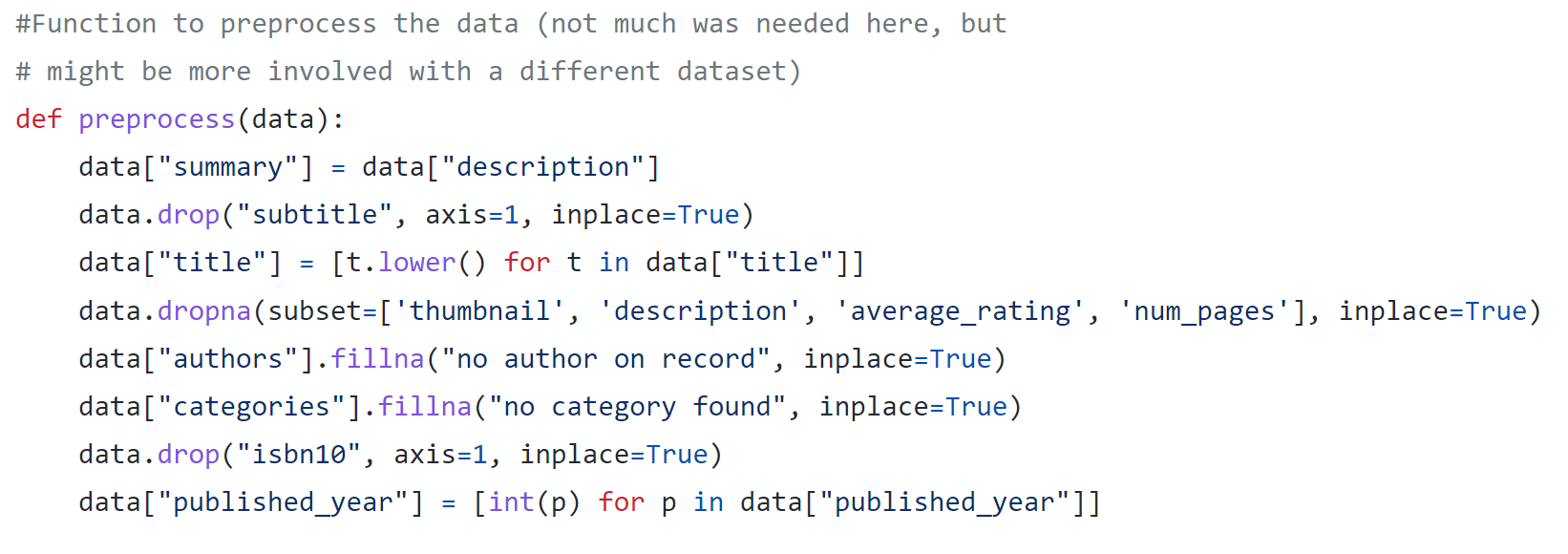
The larger dataset needed a little bit more preprocessing work. The following image shows the function I created to prepare the dataset. I started by creating a duplicate summary column like I did above in order to preserve the original. Next, I dropped the subtitle and isbn10 columns because they were not needed in this application. Similarly to the smaller dataset, I converted all of the titles to lowercase. The description and average rating columns were very important to my process for recommendations, so I decided to drop any rows missing those. Similarly, I also thought that the thumbnail and number of pages would be important for displaying the book to users, so I decided to drop any rows missing those as well. I filled the missing author and category data using a substitute string. Finally, I converted the published year to integers.
The following functions were used for both datasets to prepare for topic modelling. First, I made a function to clean the text using the nltk (natural language tool kit) and re (regular expressions) libraries. I started by converting the input to lowercase. Regular expressions can then be implemented to clean the data. The first regular expression, \d, gives any digit 0-9. So, re.sub() will substitute any number with an empty string. Similarly, the expression, [^\w\s] removes any non-alphanumeric character that isn't whitespace. I stripped any extra whitespace (such as tabs or anything like that) using strip(). Finally, the text was tokenized into smaller chunks or words (tokens) using a method from ntlk called word_tokenize().

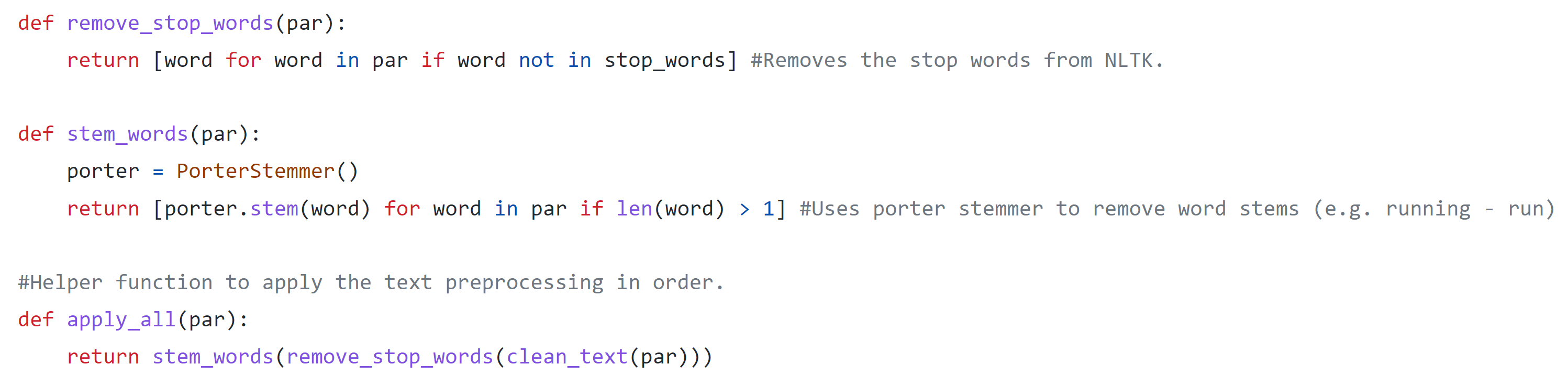
There were a few more text based preprocessing steps I wanted to do before using LDA topic modelling. First, I removed stop words. Stop words are essentially a list of really common words like "a", "the", etc. This list can be accessed from nltk. I used a simple list comprehension to remove any words matching the list of stop words. Next, I used a technique called stemming to convert each word into its root. For example, the word cats would be stemmed to simply cat. I did this by applying a Porter Stemmer, a heuristic based algorithm that removes common word endings. I used list comprehension again to apply the stemmer. I checked if the word is greater than 1 to ensure that the algorithm doesn't try to stem single character words. Finally, I created a helper function to apply all three of the functions mentioned here in order. I used this definition to apply each function to the description column in the pandas dataframe.
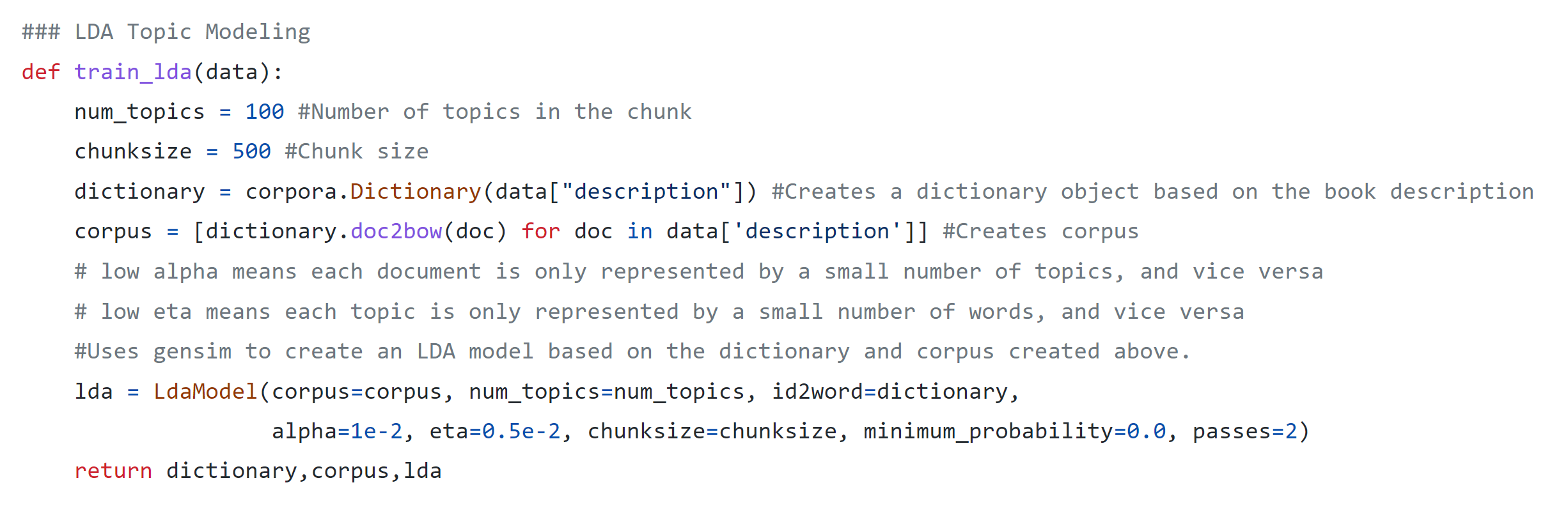
LDA stands for Latent Dirichlet Allocation. It is a method for identifying topics from a corpus that each have some probability of being correct. It is an unsupervised approach and is very useful in cases like mine where you don't necessarily know what each book is about, and don't want to read thousands of books to find out! I used a library called gensim to implement the LDA algorithm as follows. First, I chose to find 100 topics in a 500 word chunk. Next I created a dictionary object from the words actually in the book summaries. I created the corpus using a method called doc2bow() that creates a bag of words object from the documents in the corpus. This essentially counts the number of occurrences of each word to gain an understanding of their importance. Finally, the LDA object is created using gensim's LdaModel() and by passing in each of the mentioned parameters.
I used the Jensen-Shannon distance metric to determine which books are the most similar to the input. It is a common distance metric for measuring the similarity between two probability distributions, or topic distributions in our case. Using this imilarity measure, I sorted the dataframe to find the most similar books using the following code.

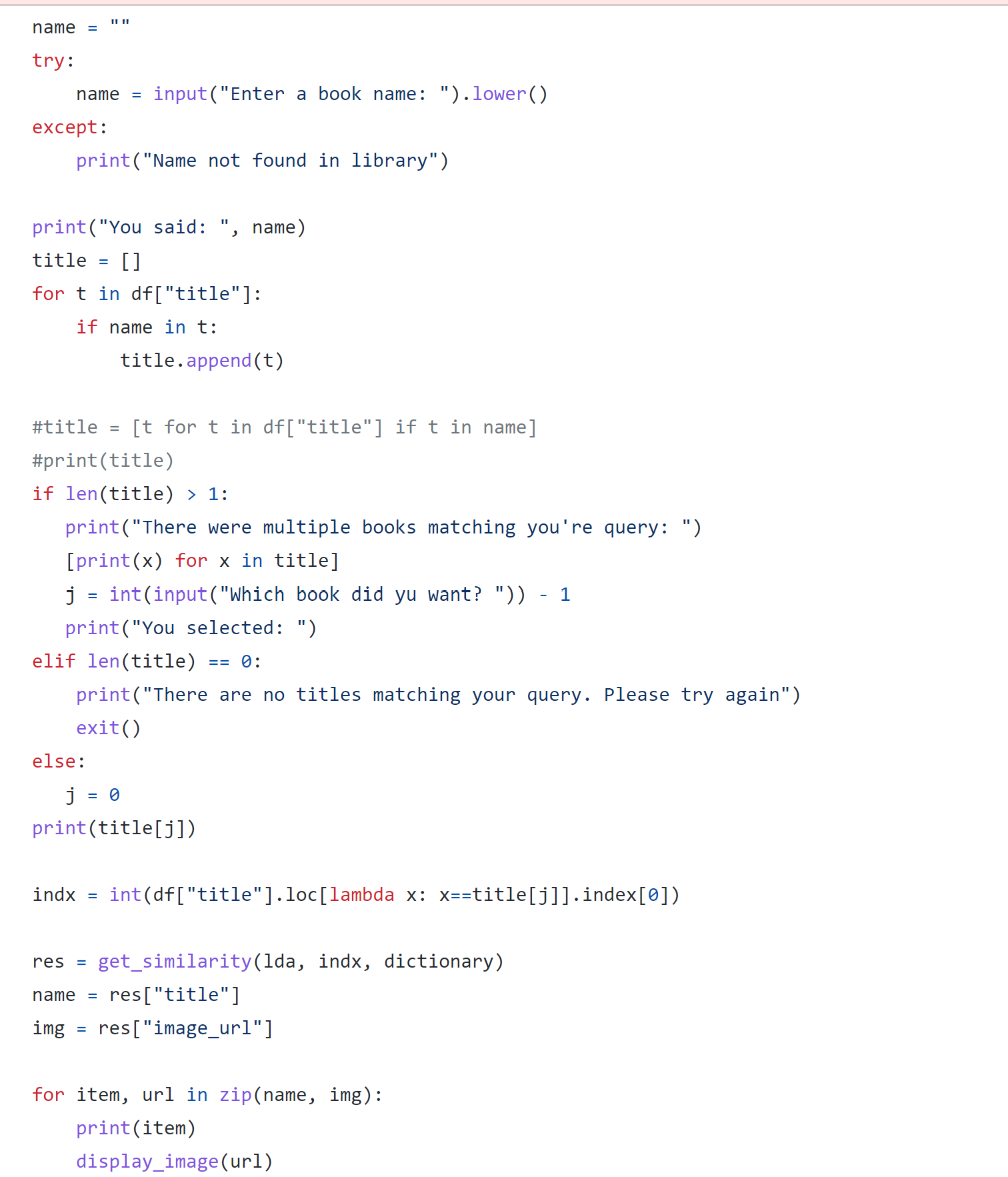
I created a simple command line interface so that users could interact with the project. In the future, I think it would be beneficial to create a web application to accompany the recomendation algorithm. I created the display using Pillow's Image function to show the book covers and command line inputs to get information from the user. This process is shown in the snippet below.